Grove, a live representation of your digital world for your agents.
Constraint
A model has training. You have experience. Training is what the model read once and froze. Experience is what happened in your Slack, your repository, your calendar, your inbox on Tuesday. The model has the first. It does not have the second.
When more than one agent operates on the same project state, the gap compounds. Every session, every agent, starts from zero: the operator re-explains who is on the team, what is shipping, what is blocked. Each agent ends up with its own version of reality: one thinks the migration shipped, another thinks it is blocked, a third thinks it shipped Friday. The only thing keeping them aligned is the operator, manually. And when the context window fills, each agent summarises and loses the file paths, the decisions, and the specifics it would have needed tomorrow.
First principles
The layer that closes this gap is not a memory product. Memory products extract facts from conversations and try to remember them. Experience is different. Experience is structured data drawn from the work itself, kept current by the work itself.
Your agents do not need a briefing. They need access to the same representation of your world that you have.
That representation has to be live (drawn from where the work happens), typed (so queries can be precise), and durable (it has to survive every session, every agent, every machine). Without those three, you are back to the operator carrying the model.
Mechanism
Sources flow in: Slack, GitHub, Google Calendar, Linear, Notion, Discord, Gmail. A pipeline parses them into a typed graph of entities (people, projects, decisions, blockers, instances, observations) and edges with explicit meanings (owns, blocks, depends on, verified at).
Two background agents do the work of keeping the graph honest.
UPDATE reads new activity from the connected sources and writes it into the graph as it happens. New decisions, new blockers, new commits, new messages. The graph grows naturally from the activity, not from a curation step.
CLEANUP walks the graph against the live source and fades, dates, or resolves nodes that no longer reflect reality. Every node carries the moment it was valid and the moment it became invalid. Stale facts are not deleted. They are dated and pushed out of the active set. This is the bi-temporal invariant that lets CLEANUP be aggressive without erasing history.
The two run sequentially. UPDATE first, CLEANUP second, once per tick.
Running today
The same loop has been running under CCL (the CEO's AI partner) for six months. The graph is the substrate that lets her pick up a thread from three weeks ago, answer a question about who owns what without being told, and refuse to repeat a question already answered. The current state of the graph:
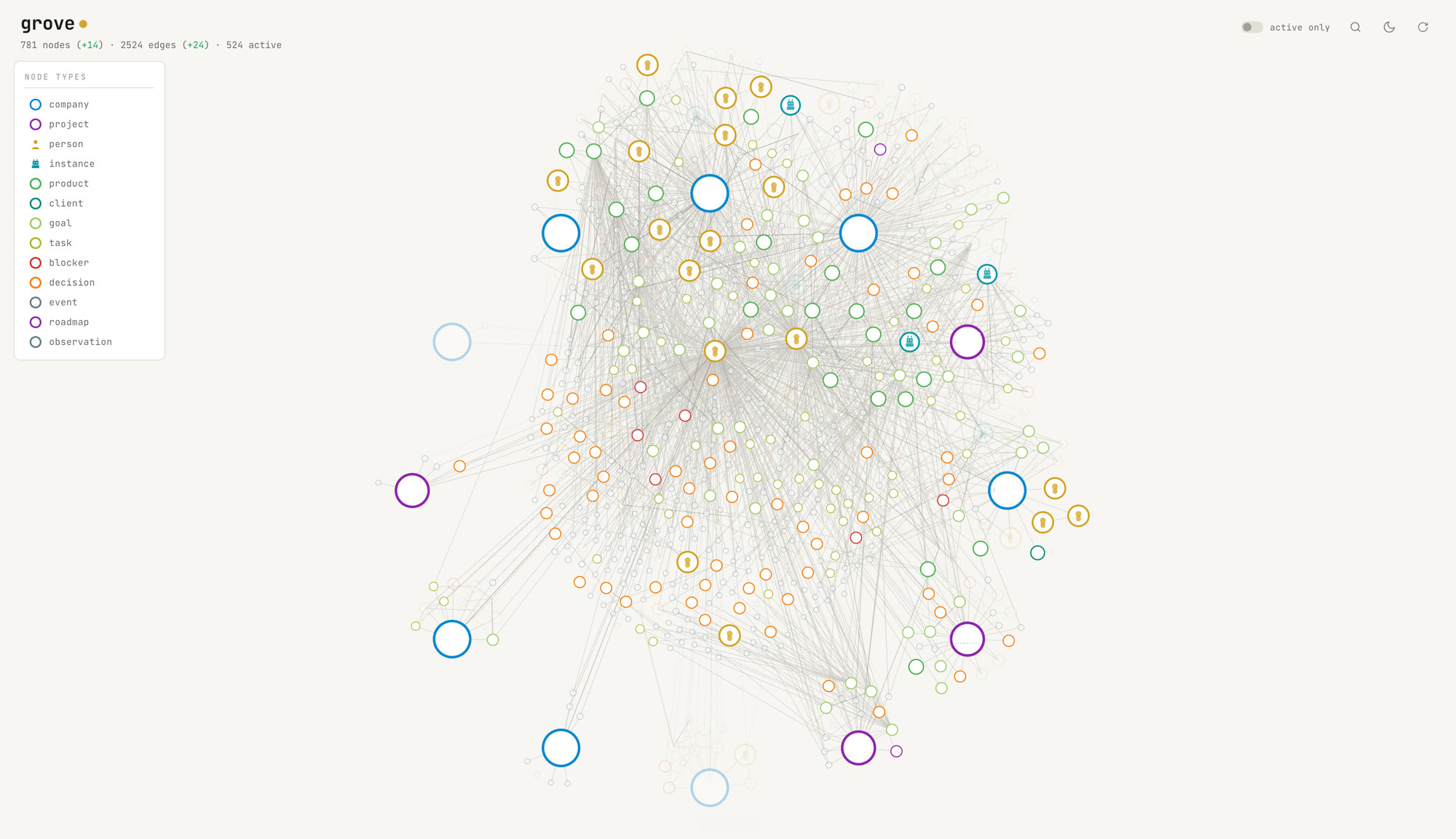
Grove is the productised externalisation of this loop. It was not built to ship. It was built to make our own agents coherent across surfaces, sessions, and machines. We are releasing it because the same problem shows up in every multi-agent setup we have run.
Benchmark
Long-term memory in AI agents has one public benchmark: LongMemEval (ICLR 2025). It scores whether a system retrieves the evidence session from a long-running chat history. The benchmark provides 470 scored questions, each with around 40 distractor sessions, and uses a single deterministic metric called session recall@5: the fraction of questions whose gold evidence session is in the top five retrieved. Every published system in this category reports against it. We ran Grove on it against the published scores from gbrain and MemPalace, using the same dataset, the same harness, and the same scorer code. The full methodology is detailed in the whitepaper.
| Grove | gbrain (hybrid) | gbrain (vector) | MemPalace (raw) | |
|---|---|---|---|---|
| LongMemEvalsession recall@5 | 99.36% | 97.60% | 97.40% | 96.60% |
The benchmark proves Grove holds its own on flat-retrieval. What it does not measure is the part Grove was built for. Public benchmarks have not caught up to relationships, time, identity, and provenance. The four layers below ship in the live system today, measured by what depends on them, not by a public bench.
- Relationships. Multi-hop traversal across typed entities — what is blocking the project owned by the person who reports to Bob?
- Time. Bitemporal state. What was true on a date. What has since been refuted. Decisions superseded.
- Identity. Alias and role resolution with confidence — the CTO, @bob, BM all land on the same node.
- Provenance. Every claim traces to its source: message, commit, meeting note. Audit-grade.
Typed, not text
Other memory layers extract memories as fuzzy text. Grove writes a typed graph. People are person nodes. Projects are project nodes. Decisions are decision nodes. Edges between them carry meanings (owns, blocks, depends on, verified at).
Typed structure costs more upfront than free text. What it buys is structurally precise queries and an audit trail that survives multi-session use. A query like which decisions still depend on a blocker that has been resolved is a graph traversal, not a fuzzy match.
Trade-offs
Grove is opinionated about typing. That is the trade-off. Free-text memory is simpler to implement and easier to dump into. Typed graphs require schema decisions and validation at write time. The pay-off is that an answer the graph returns carries the source it came from, and queries that need precision are precise.
Reconciliation across more than three concurrent agents touching the same node still surfaces consistency questions we have not closed. The current guidance is to cap concurrent writers per surface until that work lands.
Contact
If something on this page is relevant to work you are running, write to us. The form is on the landing page. We come back within two working days.
Book a discovery call →